I have the honor of leading the development of swap support in Kubernetes. This post grants you a unique opportunity to deep-dive, hand-in-hand with this feature’s main developer and leader, into the depth of swap support in Kubernetes. By reading this you would understand what happened “behind the scenes” and be able to answer questions such as what the main use cases are, how swap is implemented, how you can get involved, what the future plans are and what the swap is so difficult about it.
In case you prefer watching a recorded video, you’re lucky! I have also given a talk about this topic on DevConf 2024 @ Brno, Czech Republic: https://www.youtube.com/watch?v=hIOJz4t4tM0.
This post will contain much more details and will dive much deeper than the video though, so it’s worth reading it as well! However, it might be a bit too long for some folks. Feel free to use the table of contents below and jump to the parts you’re most interested in!
In addition, I’m always happy to get feedback. You can find the different ways to contact me in the “Get in touch” section here: iholder.net/#get-in-touch. Your feedback is much appreciated!
Without further ado, let’s jump in!
Table of contents
- Introduction (or: what's so difficult?)
- Isn't swap a thing of the past?
- Quick discussion on memory requests & limits
- Use-cases in Kubernetes
- A bit of history: back in the alpha days…
- Back to why the swap it's so difficult
- Steps towards a solution for setting swap limits
- Automatic Swap Limit Configuration
- Further features and improvements
- Current status
- Future plans
- The perfect time to get involved!
- Bonus: tips & best practices
- Summary
Introduction (or: what’s so difficult?)
During my work as a Kubevirt maintainer and a Kubernetes developer, I had interest in supporting swap in Kubernetes. “Well, it’s just enabling swap”, I thought to myself, “let’s just try to enable it, start kubelet on this node, and we’re done!”. I’ve quickly discovered how naive I was when all of my hopes shattered by looking at Kubelet exploding and bursting into flames in front of my eyes.

Let me tell you, I was pretty surprised. Swap is a pretty standard feature that is enabled by default on most machines, desktops and servers alike. In my mind, all that needs to be done is enabling swap and the Linux kernel would do the rest for us by swapping memory whenever needed. What the swap is so difficult about it causing Kubernetes developers to decide to not support swap in such an aggressive manner?

Isn’t swap a thing of the past?
Before diving into the solution, let’s first understand the need.
I mean – let’s face it – swap is considered by many to be an old technology that isn’t really necessary in modern days. Chris Dawn, in his interesting piece called “in defense of swap”, writes:
Swap is a hotly contested and poorly understood topic, even by those who have been working with Linux for many years. Many see it as useless or actively harmful: a relic of a time where memory was scarce, and disks were a necessary evil to provide much-needed space for paging 1
The truth is that swap memory is not just additional slow memory that should only be used in an absolute emergency, but rather an important mechanism that facilitates the memory manager to do its job properly and efficiently.
While the above explains why swap is important in general, there are many reasons why swap is important specifically in the Kubernetes sphere. We’ll focus on Kubernetes in the next sections below.
Quick discussion on memory requests & limits
In this quick section I’ll give a quick overview of the resource requirements in Kubernetes with emphasis on memory resources. If you’re a Kubernetes expert and feel you don’t need this refreshment, feel free to glance over this section and jump to the next one.
A quick reminder: what are memory requests & limits?
As you probably know, when defining containers in a Pod it is possible to set memory requests and limits. Memory requests represent the baseline level of memory that the container is assumed to consume during its normal operations while limits represent the maximum amount of memory that the container is able to consume.
Since setting memory requests/limits is optional, one can ask himself what’s the motivation for setting these. In Kubernetes there’s a trade-off between predictability and stability – the more a container provides more predictability and restricts itself, the more Kubernetes will make sure these resources are guaranteed. There are other benefits as well, such as having smaller chances to get evicted during node pressures.
How to set memory requests & limits?
Setting memory requests and limits is harder than it might seem. But first thing first. Let’s start with a relatively easy case. Before setting resource requirements we have to run the intended workload and profile its memory consumption. Let’s consider the following example:
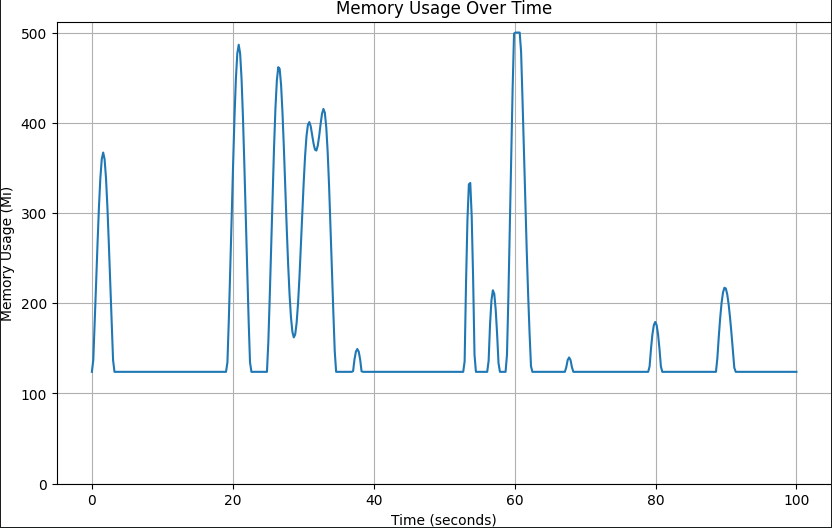
As can be seen, the minimum in this graph is around 120Mi. The memory consumption grows once in a while to the range between 200Mi and 400Mi and occasionally peaks higher, with the maximum peak reaching a bit above 500Mi.
There isn’t a single way to define memory requests and limits, but rather it depends on multiple factors such as how much we care if the pod dies at pressure, how much we care about using more node resources (which can affect cost in the public cloud) and more.
On the one end, we can define the memory request to the lowest memory consumption that was measured and set the limit to the maximum, which in this case means setting the request to 120Mi and the limit to 500Mi. If we’re more conservative, setting the request to 250Mi and the limit to 700Mi, just in case, is also reasonable.
However as written above this is a relatively easy case. Down below I will mention much harder cases (spoiler: swap can greatly help in these!).
Quiz: what happens when memory limits are reached?
Whenever I give a talk about this topic and ask the crowd this question, the answer is always “the container dies!”. Well, that answer is not wrong, but not entirely accurate either. Let me elaborate.
Under the hood the mechanism kubelet uses to ensure that a container won’t use more than its memory limits is cgroups 2, or more specifically, cgroup’s memory.max *. Whenever the set of processes that run in the container breach the memory limit, these processes are throttled and put under a heavy reclaim pressure. Only if the kernel cannot reclaim enough memory so that the consumption would become less than the limit the container gets killed **. The reason I claim that the common answer of “the container dies!” is only half-wrong is that usually there isn’t a lot of memory to reclaim. The kernel tries to drop caches, kernel structures, flush open files back to disk and such, but usually this is not a huge amount of memory and the container dies anyhow.
However, swap changes the picture dramatically. While kernel structures and caches usually do not consume huge amounts of data (certainly not dozens of Gigabytes) and having tons of very large open files are also pretty rare – swap space is usually very large. Dozens of Gigabytes is not special, for example. This increases, by orders of magnitude, the amount of memory that can be reclaimed from a container. In the next section we’ll see exactly how this helps avoid containers from crashing.
* I’m referring to cgroups v2 only in this post. In cgroup v1 the knobs are named slightly differently.
** By default, only one process is getting killed in the relevant control group. However, kubelet uses another cgroup knob which is called memory.oom.group so that the whole container would die as a single unit.
Use-cases in Kubernetes
Pages used (only) for initialization
If the previous quote wasn’t enough, here’s another quote directly from the Linux kernel documentation:
The casual reader may think that with a sufficient amount of memory, swap is unnecessary … A significant number of the pages referenced by a process early in its life may only be used for initialisation and then never used again. It is better to swap out those pages and create more disk buffers than leave them resident and unused. 3
This case is actually more common than one might think, for instance:
- A language runtime that requires access to the program’s source code arranges all the code in a separate memory arena during initialization. Once the program is initialized and the container becomes ready, this memory is no longer accessed.
- Reservation of memory in advance for custom OOM handling (which is usually never used).
- Importing shared libraries for functions used only during initialization.
While this is obviously true and important in the general case, the implications on Kubernetes environments are significant. If you’re running an on-premises cluster you often wouldn’t be able to scale compute resources easily (or at all), therefore you’d aim for the best resource utilization hence to avoid wasting memory on pages that are never used.
High costs is a known problem in the public cloud space and many seek ways of lowering those costs. If you’re running your cluster in the cloud, being accounted for more memory often leads to higher expenses which might be a big deal, especially in this case where holding this memory on RAM has no real merit.
Rare & temporary spikes at the container level

The graph we looked at above showed a case that’s fairly easy to handle, but what if we’re talking about a container that uses a close-to-constant amount of memory but every once in a while its memory consumption peaks dramatically for a short amount of time? Aside from the fact that these cases are much harder to profile, they bring a dilemma. One option is limiting memory usage to the highest memory spike possible, but this approach brings a few challenges. Firstly, if the peak is high enough it is effectively equivalent to not setting a limit at all, which is not acceptable in many cases. Additionally, the peaks might not be predictable in nature, or in other words, impossible to measure and predict.
With swap enabled this problem becomes much easier. The limit can be set to a reasonable value that we are aware that can be breached. While without swap the outcome of breaching the memory limit is almost always a crash, with swap the chances of recovering are much higher, especially when the peaks aren’t very frequent and more so if they are gradual. Avoiding crashes might lead to saving many resources depending on the situation, like re-scheduling the pod (if the restart policy is “Never”), going through a warmup phase, and more. Of course, the effect might be bigger if we’re talking about many containers running in parallel.

A special case for the case of a temporary spike is the fork-exec pattern, which is pretty common in several cases like interpreters loading a program, e.g. ruby-on-rails. In this case, the memory consumption of the program approximately doubles itself for a very short period of time. As explained above, setting the limit as twice what it should be is an option but could lead to several disadvantages.
Rare & temporary spikes at the node level
Whatever’s explained above is also relevant at the node level, that is, unpredictable infrequent peaks can occur at the node level. As an example, let’s say we have a cluster of 30Gi nodes. In addition, let’s say that we need to run a CronJob once a few days and we expect this job to consume about 20Gi of memory. Since this job consumes about 2/3 of the node’s memory (that is assumed to also run other unrelated workloads) and runs infrequently, this is very similar to the infrequent memory peak example from the previous use-case.
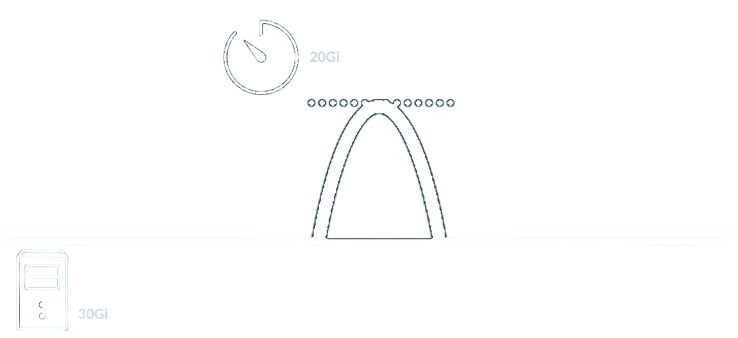
Obviously, in such a scenario we would schedule the job to run in the quietest hours, but still, we can’t guarantee that the node will have 10Gi of free memory. Without swap, either the job would be stuck on a scheduling phase without being able to land on a node (if no node has enough free memory) or it will land on a node but would cause memory pressure which in turn would lead into some pods being evicted, rescheduled onto a different node, and started again. This, of course, demands resources.
With swap, there’s a high chance that in the quietest hours some processes wouldn’t be using all of their allocated memory which would be able to be reclaimed by the OS. This way, a memory pressure could be prevented which would in turn prevent evicting workloads that are anyways, at least partly, inactive.

By the way – I bet some of you are thinking: “can’t we just horizontally scale in these situations?”. Well, sometimes we do, but on other occasions that’s not possible due to either cost reasons which could be significant. In addition, on some on-premises environments it might not be possible to scale at all.
Fast storage

Systems running with fast storage like NVMe or even SSDs may greatly benefit from enabling swap since the added overhead is very low. This is especially true for the following cases:
Development clusters: Usually during development there’s a very small emphasis on performance, therefore the added overhead is insignificant. On the other hand, running Kubernetes on a small server or even on a desktop or a laptop demands a lot of resources. Having to turn off swap only to be able to develop is both annoying and resource intensive.
Single-node clusters & nodes on the edge: Some “clusters” are single-node that cannot be scaled, e.g. in the on-premises case. In some cases it is impossible to horizontally scale the cluster but it is possible to vertically scale it by adding fast storage to the single node. By adding swap that is deployed on an NVMe storage device it is possible to effectively add more memory to the system. This is very relevant to nodes running on the edge as well, which are usually limited with their resources and cannot be easily scaled horizontally.
SSD and NVMe devices becoming popular: Lastly, some nodes already have fast storage deployed on them. With the increasing adoption of SSDs on major cloud platforms, Linux’s optimized swapping mechanisms 4, especially when combined with compression, create a new opportunity to use swap as a predictable and fast resource for additional RAM during memory pressure. Disabling swap is becoming a waste of resources, just like leaving unused RAM unallocated.
Small nodes

Kubelet, Kubernetes’ agent that’s running on each and every node in the cluster, demands a certain amount of memory in order to operate correctly. It has been reported (TODO: LINKS?) that nodes with less than 4Gi of memory don’t operate properly. This is crucial for nodes running on the edge which could be very small. As mentioned before, a lot of processes use some of their memory footprint only at initialization, and kubelet is not exceptional in that sense.
Third-party applications
Some third applications depend on swap to work properly. One example is oomd 5 which is a user-space daemon that tries to proactively take measures before the kernel OOM killer invokes. As its main developer, Daniel Xu, says 6 in his talk about oomd: “oomd monitors swap because swap is pretty essential for oomd to have enough runway to detect building memory pressure. If you don’t have swap then … you could very suddenly spike from zero to a hundred memory pressure really quickly”. oomd isn’t supported on Kubernetes yet, and swap support could lead to it being supported on Kubernetes nodes.
Kubevirt

As a Kubevirt maintainer, this is obviously the use-case that’s closest to my heart. Even more so, this is the reason I was so interested in supporting swap in Kubernetes in the first place (before I even knew there were so many other use-cases for it!).
Kubevirt is a Kubernetes extension that extends Kubernetes into being able to run Virtual Machines in a native way alongside containers. Since virtual machines are still very popular and will probably stick around for many years, Kubevirt is revolutionary in the sense that it turns Kubernetes to a common ground for different virtualization solutions like VMs and containers that can run seamlessly together on top of a single Kubernetes platform. I won’t dive into Kubevirt’s architecture here (perhaps in another post?), but very briefly, the main idea is to run a VM inside a container. In order to do so, the container runs both the guest OS itself and some infrastructure that’s needed to run it like a hypervisor (or more specifically, libvirt 7, QEMU 8 and KVM 9).

As opposed to containers, VMs have a very large dependency layer: the OS’ preinstalled applications, device drivers, libraries and much more. Another dependency that’s being carried around is the hypervisor itself which its size is not negligible.
Realistically, on a single node that runs many VM instances, the picture actually looks something like this:

As illustrated here, there’s a lot of duplication going on. This goes completely against the core idea of containers that should include only the strict dependencies that are crucial to run the application(s) inside it. To add insult to injury, this wouldn’t happen in traditional virtualization solutions since there would be only a single hypervisor instance running on the host, and not duplicated into each and every VM container. For reasons I’m not going to dive into in this post, this is not possible with Kubevirt.
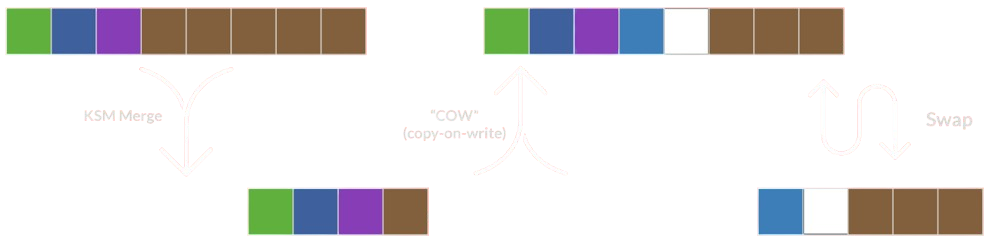
In order to solve this problem we’ve added KSM support in Kubevirt 10. KSM, which stands for Kernel Same-page Merging 11, is a mechanism that is used by the kernel in order to merge duplicated pages into a single read-only page in a copy-on-write 12 fashion. While this is very helpful, KSM by itself is dangerous in the sense that once pages are being merged, there’s no guarantee there would be enough available memory once they would be written to, therefore duplicated again. As you’ve probably guessed already, swap is a great fit for this case as well. Further to getting rid of many unused pages of the OS and the hypervisor, it serves as a safety net for the situation that merged pages are being written to and need to be duplicated.
Regularly, the VM container’s memory requests are defined by the guest memory + the infrastructure overhead
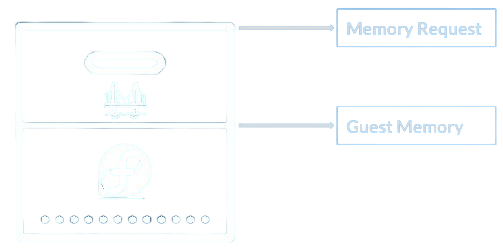
However, now that we know that some of the unused memory will be merged and swap we can increase the VM density on a node by “over-committing” 13 the memory a VM requests. This looks something like the following:
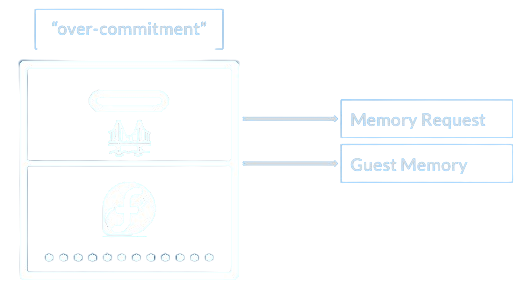
This way we increase the density of VMs and let KSM and swap do their thing. The two mechanisms work greatly together and cover up for each other. This summarizes how the two work together:
I’ve tried to convince my management to pursue swap support in upstream Kubernetes. However, in Kubernets features tend to move pretty slowly. There are a lot of eyes looking at every change, a lot of developers from different companies and with different interests are involved and sometimes it’s not easy to gain a consensus. Since this was a very high priority task that’s crucial for customers in the short term, my management was a bit hesitant about this idea.

But I went for it anyway.
Summary
As you see, there are tons of use-cases for bringing swap support into Kubernetes that are relevant for production and development environments, on-premises or in the cloud, for containers and virtual machines, for single-node clusters and on the edge.
This fact only raised my surprise around why it is not already supported and why it is such a big deal to make it happen.
A bit of history: back in the alpha days…

And so, I’ve started to look into adding swap support to Kubernetes!
Back in the day, swap support was at its Alpha stage. Turned out that the developer who started this effort was inactive for years. Swap development was discontinued, and the code was abandoned, rotting away. There was not much interest around it, it had no priority and no future plans.
If that’s not enough, it turned out that it didn’t really work, at least not in a practical way. For example, it didn’t support cgroup v2 at all (which was very popular these days), did not provide any monitoring or debug capabilities and more. I’ll mention more problems that were solved further in this post.
Long story short – it was almost as if swap was not supported at all, or at least the support was experimental and very far from being suitable for anything near production use.
Back to why the swap it’s so difficult
One of the first important realizations I’ve had is that figuring out how to limit swap usage for containers is one of the most important key elements in order to bring production grade swap support.
The thing about swap memory is that it’s by essence a system-level resource. Let me clarify what I mean by that.
Intro: the reasons a process swaps memory
In general, accessing storage is a very slow and intense process. The exact amount of time it takes to swap pages in and out changes over time and according to the specific hardware that’s being used, but in general, it’s slower by many orders of magnitude compared to dealing with main memory. For this reason, the kernel would try to be as lazy as possible with respect to reaching to the disk, and with very good reasons. In other words, the kernel will not swap pages unless it “has” to. But let me clarify what “has to” actually means.
Firstly, the system would start swapping whenever there’s a shortage of memory for the system as a whole. In this case, the kernel would try to reclaim any memory it can before OOM killing processes. One of the reclaim measures is swapping pages to disk. The kernel has several heuristics and algorithms to pick which pages are the best candidates for swapping, but the general principle is that the pages that have the lowest probability of being accessed are the ones who are being swapped out first. That way the kernel tries to ensure that pages won’t be swapped in and out often, but rather that a page that was recently swapped out would remain in the swap area for a while.
Interestingly, the same can occur at the container level as well when memory reaches its limits. More precisely, every container is composed of a cgroup, and every cgroup has different knobs (usually in the forms of files) that configure resource limitations and controls. One of these knobs is called memory.max which determines the container’s memory limit. Similarly to the system-wide case, at the container level the kernel would also try to first reclaim any memory it can once the memory limit is met before OOMing processes, and swapping out pages is one of the reclaim mechanisms available to the kernel. Another cgroup knob that’s important to know is memory.swap.max, which determines the swap memory limit for this container (obviously, in the system-wide case, the limit is the size of the swap file / partition).
But here’s where it gets really complicated – let’s zoom in on a process inside a container and try to understand what might cause the kernel to choose to swap out portions of its memory (for the sake of the example, let’s say that this container runs a single process).
Let’s consider a stressful process first, that is, a process in a container that uses a lot of memory. In one scenario, this process can cause a system-wide memory pressure. When the kernel would notice that pressure, it would seek out unused pages that most probably do not belong to this stressful process, because the process intensively uses all of its allocated memory. This would cause the kernel to swap out pages from different processes on the system. This is not necessarily true though, since the process itself might have allocated pages that are not used after its initialization (as mentioned above), then the kernel might swap out pages from the same process. However, if we’re talking about a container-level pressure with memory and swap limits (that is, memory.max and memory.swap.max are of non-zero value), the kernel would have to reclaim memory from the container itself in order to avoid OOM killing it. But even if the container is a “good citizen” that’s not stressing the memory, the kernel can decide to swap its pages because of a system-wide pressure that has nothing to do with it.
As you can tell, this all is pretty complex. If a container swaps out pages, we can’t know if it was due to a system-wide pressure or a container-level pressure, if the container is stressful or a good citizen. This background is important to understand both for this post and for further ones to come (for example about evictions. I’ll mention this at the end of the post).
Swap – a system-level resource
Especially because swapping pages is an intense process that causes an insignificant overhead, abusing it might have system-level implications that could lead to a node-level instability. Unlike regular memory, abusing swap also has side-effects like causing IO pressure which in turn can cause other containers to hang or even crash.
Consider the following scenario: a container with a tight memory limit (but no swap limits. That is, memory.max>0 but memory.swap.max=0 which means “unlimited”) is maliciously trying to bring down the node, so it allocates more and more memory to try to stress the node. Once the memory limit is met, the kernel starts swapping out pages from this container to do everything it can to avoid OOM kills. In this scenario the kernel works hard to swap out pages causing an IO pressure. Further than slowing down the whole node, other containers that do IO operations might suffer from a performance degradation in the better case and crash from timeouts in the worst case. In a similar but different case, consider a container that allocates more and more memory but doesn’t have a memory limit. In this case the kernel will most probably choose pages from different containers as candidates for swapping out, as they are more inactive, therefore have lower probability to be used in the near future. This way, further to causing an IO pressure, a single malicious container can cause pages (that might be important, for example for performance purposes) to be swapped out continuously. Obviously, in real life examples, the container doesn’t necessarily have to be malicious, but rather this can be caused by an innocent memory leak.
While there are some tricks to reduce the risk (see “best practices” below TODO), it’s still dangerous to let containers use swap without limitations.
It’s all about limits – but how to set them?
As written above, most of the problem around swap is setting swap limits. If so, the main question is how to set these limits.
One obvious line of thinking could be to introduce an API for that at the container level. In other words, just as a container can specify memory requests or limits, a container would be able to do so for swap memory.
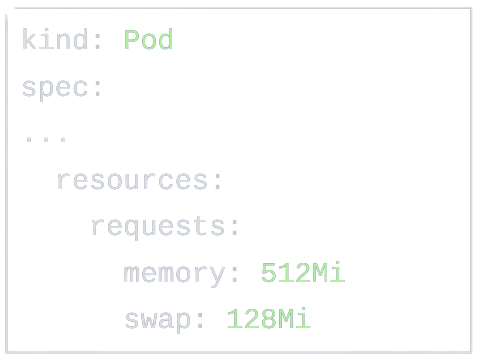
While being the first intuitive thought for many of us, this is a very bad idea. To be honest, setting memory requests and limits is hard enough as it is! Setting swap is almost impossible, at least for many use-cases. As said above, since swap is a system-level resource, pages from a container can be swapped away for external reasons that are completely outside of the container’s control and responsibility. While memory usage profiling is hard, swap memory profiling is nearly impossible and is highly unpredictable. If that’s not enough, swapping is highly machine dependent and is sensitive to characteristics like swap size, the ratio between swap and memory capacity, swappiness 14, etc.
Another reason that’s not purely technical is, of course, backward compatibility. Once API is being added to the pod spec, it’s pretty much impossible to get out, or at least extremely hard. One notorious example is the .spec.nodeName field 15 which everybody pretty much agrees is terrible, but still there’s a very strong push-back against deprecating it just because of backward compatibility reasons. For this reason, one has to be extremely confident about an additional pod-level API before adding it.
Steps towards a solution for setting swap limits
No APIs – focus on swap enablement

Further to the above, I’ve decided to go in the opposite direction – no APIs whatsoever!
In general, I was guiding a line that the current KEP 16 should revolve around basic swap enablement. More advanced topics (which I’m going to mention at the end of this post in short) are going to be addressed in follow-up KEPs. This way we would be able to progress slowly but surely and introduce a basic swap enablement which users would be able to experiment with before tackling hard issues like APIs, customizability and more. Either way, incremental changes are almost always the way to go and have many different benefits.
This approach has gained a broad consensus among the upstream community, and so I’ve put aside things like customizability and APIs for future KEPs. This means that we still have to make sure that swap is limited, but with no APIs. In other words, swap limits would need to be transparent and automatic.
“swap behaviors”
In the alpha days, the concept of “swap behaviors” was introduced. Basically, we’re talking about a kubelet-level configuration that determines how swap operates. When I began messing around with swap, there were two swap behaviors: LimitedSwap and UnlimitedSwap.
UnlimitedSwap is very simple and acts as it sounds – there is no swap limit at all. While it sounds as if it’s reasonable for an admin to configure swap that way, if you read the above you already know how dangerous this approach is. While we trust the admin to be knowledgeable, we also wish to protect him from making mistakes, especially in cases where the mistakes are sneaky and nontrivial. After some back and forth, we’ve decided to deprecate and drop this swap behavior. Again – the current approach is basic swap enablement, which in my eyes means to provide a swap mechanism that both works and is safe to use.
LimitedSwap also acts as it sounds, it limits the amount of swap memory a container can utilize, but how is the limit being determined? In the alpha days, the swap limit was configured to be the same as the memory limit. This approach is extremely problematic for various different reasons. Firstly, it gives total control to the user, which we already said is problematic. Since memory limits have no implications on scheduling, the pod owner can set the memory limit to 9999Gi, which effectively means we’re back to UnlimitedSwap again which means that the node is compromised. Furthermore, with this approach the order of scheduling matters. Let’s say that on a certain node we have a swap file of size 1Gi and container A is scheduled to this node with a memory limit of 1Gi. This container can use all of the swap space. If afterwards a second container B is being scheduled to that node, by the time it starts running the node’s swap memory is already occupied, which wouldn’t happen if container B had been scheduled to the node before container A. Finally, there’s no correlation between the memory limit and the node’s memory or swap capacity and as we’ve already said before swap is highly machine dependent.
So, while LimitedSwap sounds good in theory, we still needed a way to automatically and transparently set this limit in a way that makes sense.
Quality of Service
Let’s give a very quick reminder about the different Quality of Service classes for pods in Kubernetes then we’ll see how it relates to our dilemma.
Basically, the Best Effort class is assigned to every pod that doesn’t provide any details for CPU nor memory resources. More precisely, these are pods that do not provide requests and limits for both CPU and memory. The Guaranteed class can be considered as its complete opposite – it’s being assigned to pods that provide requests and limits for both memory and CPU, and the request equals the limit. In other words, these pods specify exactly the amount of resources they need to operate. The Burstable class is assigned to all other pods, that is, pods that specify some details about their resource consumption, but these details are not precise.

Generally speaking, in Kubernetes, there’s a trade-off between predictability and stability. The more a container is predictable with respect to its resource consumption, the more Kubernetes will make sure these resources are ready and reserved for this pod. On the opposite side of things, if a pod is not predictable, there’s a small to no guarantee regarding its resource consumption.
If we think about it, Best Effort pods are not good candidates for using swap. For starters, they are completely unpredictable with respect to their resource consumption, but even more so, in essence “best effort” means 17 that it’s okay to kill these pods when necessary and there’s no strong guarantee revolving around them. This is why the kernel shouldn’t go out of its way to prevent these pods from being killed, but rather kill them in case there is not enough memory for them.
Guaranteed QoS pods are also pretty bad candidates for using swap, for a few reasons. The first one being that the idea that the memory is guaranteed means that it’s guaranteed that the memory would be accessible to the pod right away when it needs it. The fact that the memory had been swapped away effectively means it’s currently unavailable and that the kernel has to perform intensive operations in order to make it available again. In addition to that, such pods are in essence not supposed to be able to burst. In other words, if the container is not predictable (as it promised to be!) it should be killed, while swapping means the kernel goes out of its way to avoid OOM kills.
Burstable pods, though, are perfect candidates for swapping. On the one hand, as implied by their name, although they provide some indication of their memory consumption they are expected to burst in their memory usage. When they do, it’s reasonable for the kernel to save them from crashing. On the other hand, because they provide an indication of their memory consumption, there’s a way to guess how much memory they would be needing to operate correctly, which can serve as an indication of how much swap memory they should be limited to. As a bonus, (I think that) most of the pods are burstable pods, simply because they cover the most cases of memory configurations possible for pods.
So the first decision is that only burstable pods would be able to utilize swap memory.
Memory requests vs limits
One interesting and a key difference between memory requests and limits is that only memory requests affect scheduling. In fact, memory requests (unlike limits) do not affect cgroup configuration, but instead are enforced only via the scheduler.
The scheduler makes sure that the sum of all memory requested by all pods scheduled to a certain node do not exceed the node’s available memory. This is not enforced at all for limits, which as written above are enforced via cgroup knobs which is a completely different mechanism.
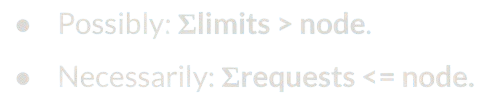
Automatic Swap Limit Configuration
So, after all of the introduction above and without further ado, let’s dive into how automatic swap limitations are being configured in a transparent, machine independent, automatic way.
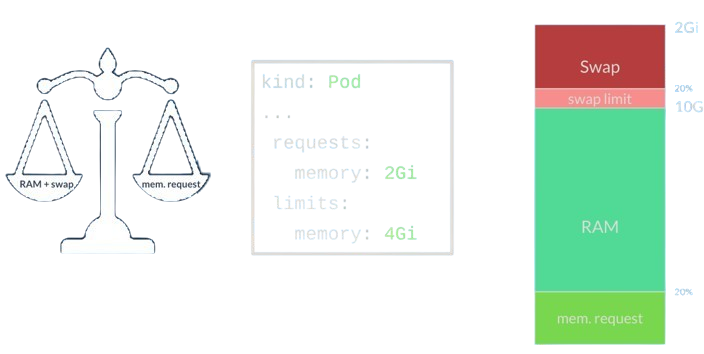
Let’s jump to the solution itself.
Let X% be the percentage of memory that the pod requests, then the pod would be limited to X% of swap memory.
In the example above, we have a node with 10Gi of memory and 2Gi of swap. The pod requests 2Gi of memory, which is 20% of the total node’s memory. Therefore, the swap limit would be configured to 20% of the swap memory, which is approximately 400Mi.
In more mathematical terms:
swap limits = memory_request * (swap_memory / node_memory) = 2Gi * (2Gi / 10Gi) = 0.4Gi
This solution is simple, yet sophisticated. It fits our demands in the sense that it’s transparent and automatic and is completely independent of both the order of scheduling and the size of the node’s memory and swap capacity. In essence, it is very much inspired from the idea of how pods are being scheduled with respect to their memory requests.
This solution has some caveats, though.
For starters, it’s possible that some of the swap’s capacity wouldn’t be able to be used by pods (i.e. if not all of the pods are of Burstable QoS). While this can be seen as a disadvantage, since there isn’t really a mechanism to reserve swap yet, this serves as a way to reserve some of the swap’s capacity for system daemons that run on the node outside of Kubernetes’ reach. In addition, there is absolutely no customizability as of now, which is a clear downside. As said above, this will be addressed in follow-up KEPs. All in all, I believe that this solution is a great fit for a first swap enablement which leaves the doors open for further extensions in the future.
Further features and improvements
While the above was the core of the issue for bringing swap support to Kubernetes, it is certainly not the only thing that was introduced around swap. In this section I will shortly outline some of the most significant improvements and features around swap support.
Monitoring, Auto-scaling and debugability
Back in the alpha days, in order to understand what’s the current swap usage for a certain pod, I had to execute bash inside this pod and start printing out the contents of cgroup’s memory.swap.current knob. You’re probably thinking, “not the best UX”, and you’re right.
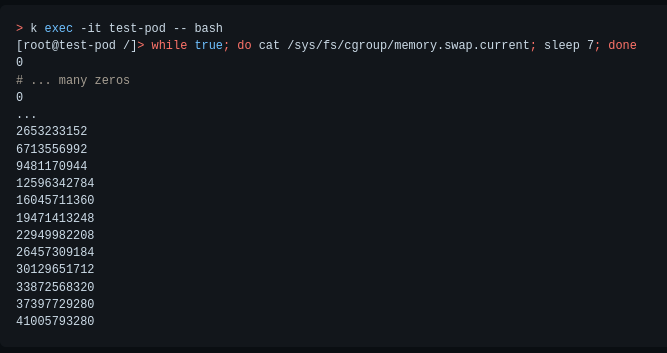
And so, firstly, we’ve added support for monitoring solutions like Prometheus via the /stats/summary endpoint. The below is a simplified output showing approximately how it would look like. As you can see, the amount of available and used swap bytes is being shown per node, pod and container. With this in place, monitoring tools like Prometheus can help debug, profile and visualize the amount of swap that’s being used by the various different workloads running on each node.

Similarly, we’ve added support for the /metrics/resource used primarily by VPAs and HPAs, or Horizontal / Vertical Pod Autoscalers. This is pretty cool, since now autoscalers would be able to perform scaling with respect to swap usage.

The problem with these metrics is that they’re more software-facing than user-facing. While this is not necessarily a problem, especially for this current basic enablement KEP, there’s a chance that we’ll be extending support for more comprehensive and user-friendly debugability capabilities. This is still under discussion.
Memory-backed volumes
This is one of the more interesting problems I had along the way. In fact, it’s one of the only points in the way where I thought to myself “maybe my managers were right and this was destined to fail”. <TODO REWRITE THIS LESS HARSHLY>.
Memory-backed volumes’ content is, well, memory-backed. From the kernel’s perspective, this memory is not special and might be swapped to disk if necessary. From a first glance this might make sense, and with good reasons, there are perfectly valid use-cases for swapping memory-backed memory, but there are other cases where it’s a serious problem.
Let’s start with the less obvious case, which is using emptyDirs. These volumes reside on-disk by default but can be configured to reside in memory (by specifying medium: Memory) by tmpfs, a file-system that resides on memory. In this case it is problematic to swap the contents to disk for two main reasons. The first one being that this goes directly against the user’s definition – the user explicitly asked for the memory to reside in memory but if it’s swapped the memory would reside on disk. Another reason is that the most common use-case for setting emptyDirs that are backed by memory is for performance reasons. Swapping the memory back from the disk to memory is a very heavy operation, therefore configuring that the content should remain in memory is useful to ensure that whenever the memory is accessed it would be in memory ready to be consumed quickly. Therefore, in this case the volume’s contents shouldn’t be allowed to be swapped to disk.
Another problematic use-case is using Secrets. For security reasons, the secret’s contents must remain in-memory and never be swapped to disk. As written in Kubernetes’ documentation: secret volumes are backed by tmpfs (a RAM-backed filesystem) so they are never written to non-volatile storage 18. If tmpfs sounds familiar it’s for a good reason, that’s the same mechanism that’s used to implement emptyDirs that reside on memory! In fact, under the hood, secrets are just emptyDirs backed by memory that are pre-populated with the data that’s configured for the secret.

So the question boils down to: how to configure tmpfs mounts that cannot be swapped to disk?
This is where I’ve started to panic a bit. When I started to look around and consult with fellow developers, I found ramfs 19. Basically, ramfs is similar to tmpfs, but it stays on RAM and cannot be swapped to disk. However, it has other problems, like being very old and primitive, does not support options and customization and more. But the most frightening of all – we’re talking about replacing the underlying mechanism that’s used to mount memory-backed volumes. This change would probably demand creating a different KEP which will take at least 3 releases to GA (and realistically much more than that) before we’d be able to move on with swap support.
After being deep in a desperation phase and almost losing hope, my fellow developer and friend told me about a new tmpfs option that’s called noswap 20! A miracle indeed. However the thrill was quickly replaced with yet another concern. As said, this new option is, well, new (supported from Linux kernel 6.4) which means that it is not supported in many environments that are still running older kernel versions.

While this is true from an upstream kernel perspective, in reality the noswap is supported in earlier versions as well for many environments. The reason is that the different Linux distributions (e.g. Fedora, Ubuntu, etc) can choose to backport this option to earlier versions. This means that realistically it’s very probable that many environments would support it although their kernel version is older than 6.4.
After many discussions regarding this, a consensus was gained regarding the following approach: If the kernel version is equal or higher than 6.4 => use noswap for memory-backed volumes. Otherwise, kubelet would try to mount a dummy tmpfs with the noswap option and look for failures. If the mount succeeds, use the noswap option. If the kernel failed with an error specifying that the option is unknown, raise a warning and move on. It’s important to mention that shortly (maybe even by the time of writing these lines) this option will be supported in pretty much every environment, or in other words, this problem is temporary and will resolve itself shortly.
And this is how another significant obstacle was overcome.
Prevent swap access for high-priority pods
After many discussions on the matter, we’ve decided to restrict access to swap for containers in high priority Pods. Pods that have a node- or cluster-critical priority are prohibited from accessing swap, even if your cluster and node configuration could otherwise allow this.
The rationale here is that swap might degrade performance in certain situations. Until swap is more customizable (“Future plans” below), we thought that this serves as a sensible default that would protect the node from performance degradation.
Current status
Graduation status
Swap was introduced as Alpha long ago in Kubernetes 1.24. Here’s the official announcement: https://kubernetes.io/blog/2021/08/09/run-nodes-with-swap-alpha/.
The Beta graduation was broken into two phases, Beta1 and Beta2 (a.k.a. Full Beta, or just Beta) as part of the drama that we encountered along the way.
Beta1 was released in Kubernetes 1.28 21. At that time, I wrote a post for Kubernetes’ blog here: https://kubernetes.io/blog/2023/08/24/swap-linux-beta/ (which is a bit outdated at this point).
The Beta version was released in Kubernetes 1.30.
As the next section outlines, this is just the beginning. The current KEP is scoped at basic swap enablement, which is important to deliver as soon as possible, but this is far from being the end. There are many future plans which will dramatically improve and extend this feature in future releases.
Interest across the ecosystem
Remember how in the alpha days there was no interest around swap while it was rotting away in the dust? Well, things are very different today!
Companies like Nvidia, Google, Meta (previously, Facebook), Intel, Apple and many more have shown great interest in swap. Github issues, Slack messages and emails are flowing in with feedback, questions, ideas and aspirations for swap to be released as soon as possible. Intel has even given a talk about swap in Kubecon EU 2024 22. In addition, it became one of the highest priority tasks from sig-node’s community perspective.
Frankly, it’s just amazing to see how the word spread around the ecosystem. This makes me confident that we will indeed grow this feature over time in many new cool and valuable ways.
How to configure and use swap?
In order to use swap, a few things need to occur.
Provision swap on the node:
First, you’ll need to provision swap on the node. This can be done by either setting up a swap partition or a swap file.
There’s a common misconception (that used to be true in the past) that swap partitions are faster than swap files. This is incorrect nowadays 23. In addition, swap files are much easier to manage, so I tend to prefer them.
Here’s an example of how to set up a swap file on the node:
dd if=/dev/zero of=/swapfile bs=128M count=32
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
swapon -s # enable the swap file only until this node is rebootedKubelet configuration
The next step would be to configure Kubelet. Here’s an example for how to configure it:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
failSwapOn: false
memorySwap:
swapBehavior: LimitedSwapLet’s unpack this example:
- The
failSwapOn: falsepart tells Kubelet to not fail during startup because swap is provisioned on the node. Note that you can also use the command line flag to achieve the same effect:--fail-swap-on=false - The “swapBehavior” part is to specify how swap behaves. Currently, there are only two behaviors available: NoSwap, which means that swap is disabled, and LimitedSwap, which means that swap is enabled with an auto-calculated limit as outlined above.
Bear in mind that if swap is provisioned on the node with a NoSwap behavior, it means that Kubernetes workloads won’t be able to access swap but other processes could. This is a good practice to let system daemons, and even kubelet itself, to swap without changing behavior for Kubernetes pods.
Run Burstable pods!
That’s it!
Now, as described above, burstable pods are automatically affected. Enjoy using swap 🙂
Please look at the tips & best practices section below for many more cool tips!
Future plans
Graduate to GA!
The next thing that’s on my mind is getting swap to graduate to a general availability state as soon as possible, with hopes to do that as early as in Kubernetes 1.32 which is the next version to be released.
When swap would reach GA it would be exposed to many more companies that would now have the confidence of using swap in production. Don’t get me wrong, many companies are already using swap in production despite it being at a Beta stage, however many companies fear from doing so and others restrict doing so according to the company’s policy.
After swap graduates to GA and its usage would probably dramatically increase, I’m confident that we’ll gain much more feedback which will help us pave the future of this feature.
Follow-up KEPs: extensions and feature evolution
Above I mentioned that the current KEP (=Kubernetes Enhancement Proposal) is scoped at basic swap enablement. This means that in the near future there’ll be a need to extend this feature with follow-up KEPs that will make it much more comprehensive. Here, I’ll outline the early thoughts about follow-up KEPs. Bear in mind that this list is composed of my very early brainstorming ideas and that the KEPs themselves might change dramatically.
Enhanced customizability: as you probably noticed, there are almost no APIs whatsoever to customize swap. While we’ve invested a lot of time figuring out what the best defaults should be, I know they can’t fit everyone and every use-case. I’ve already spoken to many swap users that wished that they could configure how swap is being used according to their special needs. For example: using memory-backed volumes that would be able to swap, using swap for non-burstable pods, specifying the explicit swap amount that a pod would be able to use and so on. I deliberately insisted on tackling these requests for follow-up KEPs to bring official swap support as soon as possible, but I absolutely agree that such customizations are crucial for many use-cases. API design is never easy, but that’s absolutely a goal for the near future.
Swap-based evictions: the memory eviction mechanism works great, but it’s designed with the assumption that swap is out of the picture. In short, the current memory eviction mechanism’s philosophy is: “The kernel would start OOM killing processes at some point. I want kubelet to evict pods with special knowledge it has regarding priorities and such. Therefore, kubelet would start evicting before the kernel starts OOM killing”. The main problem with this approach is that the kernel would start swapping only when it has to (and with good reasons! swapping to disk is a very costly operation). Therefore, setting up eviction thresholds in this way will effectively prevent swapping from happening. In the near future, we’ll present a design for a new eviction mechanism that will use other measures (Perhaps PSI – Pressure Stall Information? 24) to identify when a memory pressure is taking place while being swap-aware.
There are more ideas in my head, but I don’t want to speak about ideas that are too raw 🙂
If there’ll be demand for it, I will surely publish more blog-posts about these KEPs by the time they’ll be introduced!
The perfect time to get involved!
If you wish to get involved, this is absolutely the perfect time to do so.
Not every day you get to a point of time where such a significant feature hasn’t reached GA yet, but is about to, with many follow-up KEPs that are just about to get introduced.
If you can think of:
- Use-cases
- Feedback
- Ideas
- Criticism
- Anything that’s on your mind…
Please let me know! You have the power to pave the future for this crucial feature, which might help you fit it to your and your company’s needs and use-cases.
Join us in paving the future!
You can find the different ways to contact me in the “Get in touch” section here: iholder.net/#get-in-touch.
Bonus: tips & best practices
Enabling swap for non-Kubernetes processes
As previously mentioned, it is entirely appropriate to enable swap exclusively for non-Kubernetes workloads. These processes might include system daemons or management tasks that handle both critical functions and lower-priority, yet important, activities such as periodic maintenance.
One of these daemons is kubelet itself, which as any other process, may allocate memory that’s not always needed and is a good candidate for swapping.
Disable swap for system critical daemons
In the opposite direction from the above, you might want to disable swap for high priority system critical daemons. As we were testing swap, we found degradation of services if you allow system critical daemons to swap. This could mean that kubelet is performing slower than normal, for example. So if you experience this, it’s recommended to set the cgroup for the system slice to avoid swap (i.e. memory.swap.max=0).
Protect system critical daemons for iolatency
Disabling swap for system critical daemons might not be enough.
As we disabled swap for system slice, we saw cases where the system.slice would still be impacted by workloads swapping. This occurs because swapping, which involves writing to and from the disk, is an intensive I/O operation that can deplete the node’s I/O resources. Consequently, if heavy swapping operations are in progress, other containers requiring I/O may experience resource starvation and slowdowns.
The workloads need to have less priority for IO than the system slice. Luckily, this is solvable with cgroups that can give different IO priority for different slices. Setting io.latency for system.slice fixes these issues.
See io-control for more details.
Control Plane Swap
It is only recommended enabling swap for the worker nodes. The control plane contains mostly Guaranteed QoS Pods, so swap may be disabled for the most part. The main concern would be swapping in the critical services on the control plane which can cause a performance impact.
Use of a dedicated disk for swap
It is recommended using a separate disk for your swap partition/file and that disk will be encrypted. If swap is on a partition or the root filesystem, workloads can interfere with system processes needing to write to disk. If they occupy the same disk, it’s possible processes can overwhelm swap and throw off the I/O of kubelet/container runtime/systemd, which would affect other workloads. Swap space is located on a disk so it is imperative to make sure your disk is fast enough for your use cases.
Opt-out of swap for specific containers in Burstable Pods
It’s possible to opt-out of swap for specific containers in Burstable pods by defining a memory limit that’s equal to the memory request. In a situation where we don’t really have APIs or ability to customize swap, it serves as a hint for the system to opt-out from swap for specific containers.
Summary
After overcoming so many obstacles and challenges along the way, Swap is now Beta in Kubernetes, and will soon reach GA. The work will not be done there, but would just start, with exciting follow-up KEPs. This feature’s life-cycle has just started and I’m sure it has much to evolve over time.
You can find the different ways to contact me in the “Get in touch” section here: iholder.net/#get-in-touch. I will appreciate your feedback very much!

- Chris Dawn: In defense of swap [↩]
- cgroups on Wikipedia [↩]
- Linux kernel documentation: swap management [↩]
- Making swapping scalable: https://lwn.net/Articles/704478 [↩]
- oomd on Github: https://github.com/facebookincubator/oomd [↩]
- Daniel Xu’s talk on oomd: https://www.youtube.com/watch?v=8LmlYwR0HAI [↩]
- libvirt: https://en.wikipedia.org/wiki/Libvirt [↩]
- QEMU: https://en.wikipedia.org/wiki/QEMU [↩]
- KVM: https://en.wikipedia.org/wiki/Kernel-based_Virtual_Machine [↩]
- KSM in Kubevirt’s user-guide: https://kubevirt.io/user-guide/cluster_admin/ksm [↩]
- KSM on Wikipedia: https://en.wikipedia.org/wiki/Kernel_same-page_merging [↩]
- copy-on-write on Wikipedia: https://en.wikipedia.org/wiki/Copy-on-write [↩]
- Kubevirt node over-commitment’s user-guide page: https://kubevirt.io/user-guide/compute/node_overcommit [↩]
- What Is Swappiness on Linux? https://www.howtogeek.com/449691/what-is-swapiness-on-linux-and-how-to-change-it [↩]
- my discussion on .spec.nodeName on Github: https://github.com/kubernetes/enhancements/issues/3521#issuecomment-2018362227 [↩]
- Swap enablement KEP-2400: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2400-node-swap/README.md [↩]
- Best-effort https://en.wikipedia.org/wiki/Best-effort_delivery [↩]
- Secret docs about not residing on disk: https://kubernetes.io/docs/concepts/storage/volumes/#secret [↩]
- ramfs kernel docs: https://www.kernel.org/doc/Documentation/filesystems/ramfs-rootfs-initramfs.txt [↩]
- tmpfs kernel docs: https://www.kernel.org/doc/html/latest/filesystems/tmpfs.html [↩]
- Blog-post I wrote to kubernetes.io about swap reaching Beta: https://kubernetes.io/blog/2023/08/24/swap-linux-beta/ [↩]
- Intel’s talk on swap, kubecon EU 2024: https://www.youtube.com/watch?v=El94Z0JowF0 [↩]
- Swap file vs swap partition – swap file is just as fast: https://www.baeldung.com/linux/swap-file-partition [↩]
- PSI – Pressure Stall Information kernel docs: https://docs.kernel.org/accounting/psi.html [↩]